Allgemeines
Die Applikation Regulytics® von RiskDataScience ermöglicht die automatisierte Analyse juristischer und interner Texte nach inhaltlichen Gesichtspunkten.
Bei der auf dieser Website eingerichteten App handelt es sich um eine frei bedienbare und im Umfang eingeschränkte Version von Regulytics. Der Fokus liegt hierbei exemplarisch auf den Bauordnungen der deutschen Bundesländer.
Diese können damit objektiv auf Ähnlichkeiten untersucht werden. Ähnliche Paragraphen in den verschiedenen Texten können ebenso ermittelt werden wie Unterschiede.
Nähere Erläuterungen zu Hintergrund und Motivation semantischer Analysen finden Sie hier.
B2B-Kunden können einen kostenlosen Test-Account für die erweiterte Online-Version von Regulytics beantragen, dessen Schwerpunkt auf für den Finanzdienstleistungssektor relevanten Regelungen liegt.
Die Offline-Version von Regulytics bietet darüber hinaus die Möglichkeit beliebige weitere Texte mit zu berücksichtigen.
Desweiteren unterstützen wir unsere Kunden gerne im Rahmen von Beratungsprojekten bei der Einführung semantischer Analysen komplexer wie auch umfangreicher Texte.
Bedienung
Die Lösung ist einfach und unkompliziert zu bedienen. Sprachen sowie Start- und Zieltext können über Dropdown-Menüs ausgewählt werden.
Eine weitere Eingabe ist die Anzahl der Themen für das natürliche Sprachverarbeitungsmodell (wir empfehlen Werte zwischen 100 und 500).
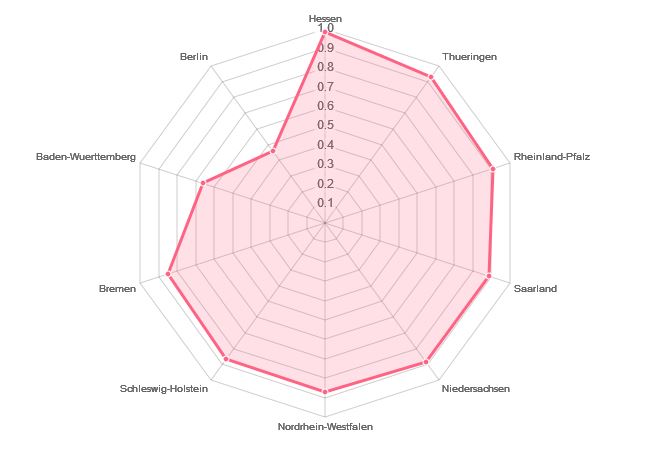
Basierend auf diesen Eingaben werden - nach einiger Rechenzeit, die je nach Serverauslastung auch bei einer halben Minute liegen kann - die allgemeinen Ähnlichkeiten berechnet und grafisch als Radar-Diagramm angezeigt (siehe Diagramm unten); das Maß hierfür ist dabei die Kosinus-Ähnlichkeit.
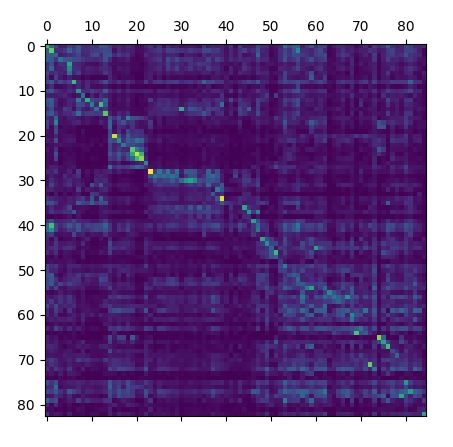
Nach Auswahl eines "Startparagraphen" im Starttext wird die vollständige Ähnlichkeitsmatrix für alle Absätze berechnet. Helle Bereiche entsprechen hierbei ähnlichen Paragraphen zwischen Start- (x-Koordinate) und Zieltext (y-Koordinate; siehe Bild unten).
Außerdem werden Auszüge der Top 10 der ähnlichsten Absätze (des Zieltextes) zum Startabsatz angezeigt. Es werden auch Auszüge der Paragraphen des Starttextes mit den höchsten und niedrigsten Ähnlichkeiten mit dem Zieltext ("Start" bzw. "Target") gezeigt. So können Überschneidungen sowie Unterschiede zwischen Vorschriften leicht identifiziert werden. Zudem werden für alle Auszüge die Kosinus-Ähnlichkeiten angegeben.
Wichtiger Hinweis: Bei der Bestimmung von ähnlichen und unterschiedlichen Absätzen sollte das quantitative Kosinus-Ähnlichkeitsmaß immer im Auge behalten werden.
Wenn z.B. der ähnlichste Paragraph zu einem bestimmten Paragraphen eine Ähnlichkeit von weniger als 0,5 aufweist, kann in den meisten Fällen angenommen werden, dass es keine tatsächliche Ähnlichkeit gibt, d.h. kein ähnlicher Paragraph existiert.
Gleiches gilt für die Bestimmung von Unterschieden.
Eine Bestimmung von unteren (für Ähnlichkeiten) und oberen Kosinus-Ähnlichkeitsgrenzen (für Unterschiede) ist möglich und sinnvoll, hängt aber von der jeweiligen Fragestellung ab.
Die Vollversion unserer Applikation Regulytics eignet sich zur inhaltlichen automatisierten Analyse beliebiger Texte. Wir unterstützen unsere Kunden bei diesbezüglichen Fragestellungen. Gerne erläutern wir unseren Ansatz auch im Rahmen eines Vorab-Workshops.
Kontakt
Dr. Dimitrios Geromichalos
Founder / CEO
RiskDataScience GmbH
Nördliche Münchner Straße 47, 82031 Grünwald
E-Mail: riskdatascience@web.de
Telefon: +4989322096365
Twitter: @riskdatascience
Regulytics® ist beim Deutschen Patent- und Markenamt als Marke eingetragen.